[Exadata day2] Exadata 핵심기능 및 초기 설정
4~6장: 핵심 기능 및 초기 설정
- 4장: Smart Scan, Smart Flash Cache, PMEM 등 Exadata 성능 최적화 기술
- 5장: 설치 전 준비(OEDA 사용), 초기 설치 및 배포 절차
- 6장: 스토리지 서버(Cell) 구성 — CellCLI, Grid Disks, ASM Disk Group 설정
Classic Database I/O and SQL Processing Model

📊 전통적인 DB(SQL) 처리 방식이란?
예전 방식의 데이터베이스 시스템에서는 “모든 똑똑한 처리”가 데이터베이스 서버 안에서만 이뤄집니다.
즉, 저장소(스토리지)는 단순히 데이터를 보관만 하고, 실제 연산은 모두 서버가 처리하죠.
🧭 예시: 테이블에서 데이터 검색(SELECT)할 때의 처리 과정
- 사용자가 SELECT문 실행
→ 예: “이 조건에 맞는 고객 정보만 보여줘!” - DB가 해당 데이터 위치 확인
→ 어떤 파일·영역(Extent)에 이 테이블이 저장돼 있는지 찾아냅니다. - DB가 스토리지에 읽기 요청
→ 테이블이 저장된 모든 블록(데이터 조각)을 읽어오라고 요청합니다. - 모든 블록을 메모리로 가져옴
→ 조건에 맞는 데이터만 필요한데도, 테이블 전체 블록이 메모리로 올라옵니다. - DB 서버에서 조건 필터링 작업
→ 가져온 데이터 중에서 SELECT 조건에 맞는 행만 찾습니다. - 필요한 행만 사용자에게 반환
→ 최종적으로 원하는 결과만 보여집니다.
⚠️ 비효율이 생기는 이유
- 조건에 맞는 데이터만 필요한데도 → 테이블 전체를 읽어야 함
- 이 과정에서 네트워크로 데이터가 대량 전송되고 메모리를 많이 차지함
- 즉, 불필요한 데이터 I/O(읽기 작업)가 엄청나게 발생함
- 결과적으로 속도 저하, 서버 부하 증가, 처리 효율 저하로 이어집니다.
✅ 정리하자면
“조건에 맞는 데이터만 딱 읽는 게 아니라, 테이블 전체를 읽은 뒤에 걸러내는 방식”이라서 비효율적입니다.
특히 큰 테이블일수록 이런 낭비가 커지고, 시스템 성능에 영향을 줍니다.
Exadata Smart Scan Model
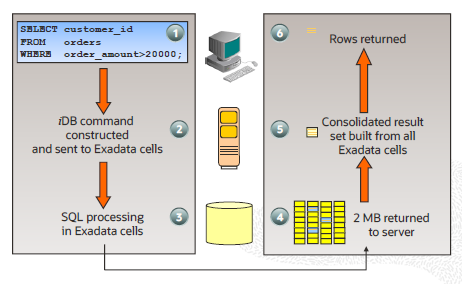
⚡ Exadata Smart Scan이란?
Oracle Exadata는 기존 방식과 달리, 단순히 데이터를 저장만 하는 게 아니라 스토리지(저장장치) 자체에서 데이터를 먼저 걸러주는 똑똑한 방식을 사용합니다.
즉, 필요한 데이터만 서버로 보내기 때문에 속도도 빠르고 자원 낭비도 훨씬 줄어듭니다.
🧭 Exadata Smart Scan의 처리 과정
- 사용자가 SELECT문 실행
→ 예: “특정 조건에 맞는 고객 정보만 보여줘!” - DB가 Exadata 저장소에 명령 전달
→ 이 데이터가 Exadata 셀에 있으면, 서버가 iDB라는 특수 명령으로 직접 스토리지에게 작업을 시킵니다. - 스토리지에서 먼저 필터링 작업
→ Exadata가 **필요한 행(Row)**과 **필요한 컬럼(Column)**만 미리 골라냅니다.
→ 즉, 조건에 안 맞는 데이터는 아예 서버로 올라오지 않음❌ where절 처리함 - 필요한 데이터만 서버로 전송
→ 기존처럼 블록 단위가 아니라, 결과만 요약해서 iDB 메시지로 전달합니다.
→ 버퍼 캐시에 블록을 저장할 필요도 없습니다. - DB 서버에서 결과 합치기
→ 여러 Exadata 셀에서 온 결과를 병렬 처리처럼 합쳐 최종 결과를 만듭니다. - 사용자에게 결과 전달 ✅
💡 이렇게 하면 좋은 점
- 📉 불필요한 I/O가 거의 없음 → 테이블 전체를 읽지 않음
- 🧠 CPU 사용량 절감 → 서버는 결과만 합치면 되니까 가벼워짐
- ⚡ 쿼리 속도 향상 → 큰 테이블도 빠르게 조회 가능
- 📈 더 많은 요청을 동시에 처리 가능
전통 방식 vs Exadata Smart Scan
| 데이터 필터링 위치 | DB 서버에서 처리 | 스토리지(Exadata)에서 처리 |
| I/O 발생량 | 테이블 전체 블록 전송 | 필요한 데이터만 전송 |
| CPU 사용량 | 서버에서 많은 연산 수행 | 서버 부담 감소 (스토리지에서 전처리) |
| 속도 | 느릴 수 있음 (대량 데이터 전송 때문) | 빠름 (필요한 결과만 전송) |
✅ 정리하자면
Exadata Smart Scan은 “필요한 데이터만 똑똑하게 골라서 보내주는” 기술입니다.
덕분에 쿼리 성능이 대폭 향상되고, 서버 자원도 절약할 수 있습니다.
Smart Scan vs Index Scan ?
🧭 1. Index Scan 이란?
Index Scan은 말 그대로 “인덱스”를 이용해서 필요한 데이터 위치만 찾아 읽는 방식입니다.
📌 동작 방식
- DB는 인덱스를 검색해서 조건에 맞는 ROWID(데이터의 위치)를 찾습니다.
- 그 위치로 가서 필요한 데이터 블록만 읽어옵니다.
- 조건에 맞는 데이터를 추출해서 사용자에게 전달합니다.
📊 장점
- 필요한 데이터가 적을 때 매우 빠름 ✅
- 불필요한 블록을 거의 읽지 않음 (정확한 위치 접근)
⚠️ 단점
- 매우 많은 데이터를 읽을 경우, 인덱스를 통해 건건이 찾아가야 하므로 오히려 느릴 수 있음.
- Full Table Scan보다 비효율적일 수도 있음(랜덤 I/O 증가).
⚡ 2. Smart Scan 이란?
Smart Scan은 Exadata에서만 가능한 방식으로, 스토리지에서 먼저 필터링해 불필요한 데이터를 아예 안 올리는 방식입니다.
📌 동작 방식
- 서버는 SELECT 조건을 Exadata 스토리지에 전달합니다.
- Exadata가 스토리지 단에서 조건에 맞는 행과 컬럼만 추출합니다.
- 필요한 데이터만 서버로 전달합니다.
📊 장점
- 테이블이 크고, 조건이 있는 Full Table Scan일 때 매우 효율적 ✅
- 불필요한 I/O 최소화, 네트워크 부하 적음, 속도 빠름
⚠️ 단점
- 인덱스를 쓰는 상황(소량의 특정 행 검색)에는 Smart Scan이 굳이 필요 없음.
- Smart Scan은 주로 대량 데이터 조회에서 성능이 극대화됨.
🆚 Index Scan vs Smart Scan
| 처리 위치 | DB 서버 | 스토리지(Exadata 셀) |
| 대상 데이터 양 | 소량의 특정 데이터에 적합 | 대량 데이터 + 조건 검색 시 유리 |
| I/O 방식 | 인덱스를 통해 필요한 블록만 랜덤 접근 | 스토리지에서 먼저 필터링 후 최소 데이터만 전송 |
| CPU 부하 | 서버 CPU 사용 | 스토리지에서 분산 처리 → 서버 부담 적음 |
| 사용 시점 | WHERE 절로 특정한 데이터만 찾을 때 | Full Table Scan 시 성능 극대화 (조건 필터링 있음) |
| 대표 예 | “ID = 12345” 한 건 찾기 | “매출 100만원 이상 고객 전체 조회” 같이 대량 검색 |
💡 정리하자면
- 👉 Index Scan → 소량의 특정 데이터를 찾을 때 유리 (인덱스 활용)
- ⚡ Smart Scan → 대량 데이터를 조건으로 걸러낼 때 유리 (스토리지에서 필터링)
✅ 팁:
- Exadata 환경에서도 소량 데이터라면 Index Scan이 Smart Scan보다 빠를 수 있습니다.
- 반대로 수십~수백만 건 이상을 조회할 때는 Smart Scan이 압도적으로 빠릅니다.
Exadata Storage Index
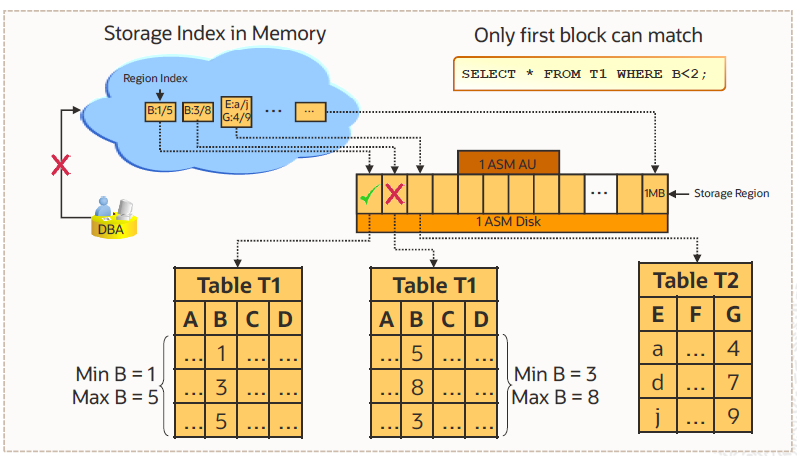
🧠 1. Storage Index란?
“**스토리지(저장소)**에 있는 데이터의 최솟값/최댓값 정보를 기억해두고,
조건에 안 맞는 영역은 아예 읽지 않게 해주는 기능”
기존에는 모든 블록을 읽은 후에 조건에 맞는 데이터를 걸러냈지만,
Storage Index는 읽기 전에 “이 영역은 볼 필요 없어”라고 미리 판단합니다.
📦 2. 내부 구조 (간단 버전)
- Exadata의 디스크는 1MB 단위로 잘게 나뉘어 있는데, 이를 Storage Region이라고 합니다.
- 각 Region마다 **최솟값(MIN)**과 최댓값(MAX) 정보를 메모리에 저장해둔 것이 Region Index입니다.
- 여러 Region Index를 모은 것이 바로 Storage Index예요.
👉 예:
| 1MB 1 | 1 | 5 |
| 1MB 2 | 3 | 8 |
쿼리 시 이 정보를 기준으로 읽을지/건너뛸지 판단합니다.
🪄 3. Storage Index의 장점
- 💨 불필요한 I/O 제거 → 디스크에서 덜 읽으니 빠름
- 🧠 서버 부하 감소 → 읽을 게 줄어드니 CPU/메모리 절약
- ⚡ 자동으로 관리됨 → DBA가 따로 인덱스를 만들 필요 없음
🧱 4. 특징 & 제약사항
| 관리 필요 여부 | ❌ 없음 — 자동으로 생성/삭제 |
| 작동 시점 | Smart Scan 시 자동 활용 |
| 데이터 유형 제한 | 숫자(NUMBER), 날짜(DATE), 문자열(VARCHAR2) 등은 가능 단 NLS 의존 타입은 불가 |
| 사라지는 시점 | 메모리에만 존재 → 셀이 재부팅되면 사라짐 |
| 복구 방식 | 재부팅 후 첫 쿼리 시 자동 재생성 |
| 가장 효과적인 상황 | - 데이터가 정렬되어 있거나 잘 클러스터링된 경우 - WHERE 절에 =, <, > 조건이 있는 경우 |
🧠 5. Cold vs Hot, Smart Scan과의 관계
- Storage Index는 Smart Scan과 함께 작동합니다.
- Smart Scan이 실제로 데이터를 읽는 동안 Storage Index는
“이 구간은 읽지 말자” 하고 범위를 건너뛰는 역할을 합니다. - 따라서 대량의 Full Table Scan + 조건 검색에서 효과가 극대화됩니다.🔥
✅ 한 줄 정리
📌 Storage Index = 읽기 전 필터링 장치
블록을 읽기 전에 조건에 맞는지 미리 확인 → 불필요한 I/O를 스킵 → 쿼리 속도 ↑, 자원 ↓
B-Tree Index vs Storage Index
🆚 1. B-Tree Index (일반 인덱스)
📌 “필요한 데이터의 위치를 직접 찾아가는 방식”
⚙️ 동작 방식
- 사용자가 WHERE 조건이 있는 쿼리를 실행
예: -
SELECT * FROM T1 WHERE B = 3;
- 옵티마이저가 해당 컬럼에 인덱스가 있는지 확인
- B-Tree 인덱스를 탐색하여 조건에 맞는 ROWID(실제 데이터 위치) 검색
- 찾은 ROWID로 테이블 블록에서 해당 데이터만 읽어옴
- 결과를 사용자에게 반환
👉 즉, 인덱스를 이용해 원하는 데이터를 “정확히 찾아가는” 방식이에요.
📊 특징
- 데이터 소량 조회에 매우 효율적 (랜덤 I/O)
- WHERE 조건이 인덱스 컬럼에 있어야 함
- 인덱스 생성·관리 필요 (DBA 개입)
⚡ 2. Storage Index (Exadata 전용)
📌 “읽기 전에 불필요한 범위를 미리 건너뛰는 방식”
⚙️ 동작 방식
- 쿼리가 들어오면, Exadata의 Storage Index에서
각 Region(1MB 단위)의 컬럼 MIN/MAX 값을 확인 - 조건에 절대 부합하지 않는 구간은 아예 읽지 않음
예: MIN=3, MAX=8 인 영역에 B<2 조건이 있으면 스킵 - 조건에 맞을 가능성이 있는 영역만 Smart Scan으로 읽음
- 필터링된 결과만 서버로 전송
👉 즉, “읽고 찾는” 게 아니라 “읽기 전에 걸러내는” 방식이에요.
📊 특징
- 대량 데이터 + 조건 검색 시 효과적
- 인덱스 생성 필요 없음 (자동)
- 정렬(클러스터링)이 잘 된 데이터일수록 효과 극대화
- Smart Scan 시에만 작동
🧭 3. 동작 방식 비교 요약
| 목적 | 원하는 데이터 정확히 찾아감 | 불필요한 범위를 미리 걸러냄 |
| 접근 방식 | 인덱스를 탐색해 ROWID로 직접 접근 | MIN/MAX 정보로 조건에 안 맞는 블록을 Skip |
| 처리 위치 | DB 서버에서 처리 | Exadata 스토리지에서 필터링 |
| 데이터 양 | 소량 데이터 조회에 유리 | 대량 데이터 + 조건 검색 시 유리 |
| 관리 필요 여부 | 인덱스 생성·관리 필요 | 자동 (사용자 개입 없음) |
| 작동 시점 | 옵티마이저가 인덱스 선택 시 | Smart Scan 시 |
| 결과 | 필요한 데이터만 읽음 | 필요 없는 영역을 스킵하고 나머지 읽음 |
🧠 핵심 정리
- 🪜 B-Tree Index
→ “목표 지점만 정확히 찾아간다”
→ 소량 조회에 강함 (랜덤 I/O) - 🧹 Storage Index
→ “볼 필요 없는 구간은 애초에 안 본다”
→ 대량 스캔 시 빠름 (불필요한 I/O 감소)
👉 둘 다 인덱스지만,
- B-Tree는 찾는 도구
- Storage Index는 걸러내는 필터라고 이해하면 정확합니다 ✅
Hybrid Columnar Compression

1. Hybrid Columnar Compression이란?
📌 행(Row) 단위가 아닌 컬럼(Column) 단위로 압축하는 방식.
- 기존 압축은 **행 기반(row-based)**으로 압축합니다.
- HCC는 같은 컬럼의 값들을 모아 압축하기 때문에 패턴이 잘 맞아 압축률이 훨씬 높습니다.
- 특히 대량 데이터를 저장하는 데이터 웨어하우스(DW) 환경에서 효과가 큽니다.
🧭 2. 적용 위치
HCC는 아래 위치에서 설정할 수 있습니다.
- ✅ 테이블 단위
- ✅ 파티션 단위
- ✅ 테이블스페이스 단위
👉 즉, 필요한 범위에만 적용할 수 있어 유연합니다.
⚙️ 3. 압축 모드 2가지
| 🏭 Warehouse Compression | 쿼리 성능에 최적화 | DW(분석) 환경 | 중간~높음 | 낮음 |
| 📦 Online Archival Compression | 압축률 극대화 | 거의 변하지 않는 데이터 | 매우 높음 | 높음(압축/해제 시) |
- Warehouse 모드 → 분석용 쿼리 속도도 빠르고 압축도 잘됨
- Online Archival 모드 → 자주 쓰이지 않는 ‘콜드 데이터’ 보관에 최적
🧱 4. 작동 방식 (간단 예시)
기존 방식:
HCC 방식:
👉 컬럼 단위로 묶어서 압축하면 반복되는 값을 효과적으로 줄일 수 있어
👉 저장 공간 절약, 읽기 시 더 적은 블록으로 많은 데이터 처리 가능
🧰 5. 실무 활용 포인트
- 🔸 파티셔닝과 병행해서 운영 가능 → 예: 최신 데이터는 OLTP 압축, 과거 데이터는 HCC
- 🔸 DBMS_COMPRESSION 패키지의 Compression Advisor로 예상 압축률 확인 가능
- 🔸 압축된 데이터는 Smart Scan과 함께 작동 → 성능 이점 극대화
- 🔸 자주 수정되는 데이터엔 적합하지 않음 (압축 해제·재압축 비용 발생)
🆚 6. HCC vs 기존 압축 비교
| 압축 단위 | 행 기반 | 컬럼 기반 |
| 압축률 | 보통 | 매우 높음 |
| 성능 최적화 | DML(수정) | SELECT(조회) |
| 사용 시나리오 | 트랜잭션 처리 | DW·아카이브·콜드 데이터 |
| Smart Scan 호환 | 일부 | ✅ 완벽 호환 |
💡 정리하자면
📌 Hybrid Columnar Compression = “컬럼 단위로 묶어 고압축 + 빠른 읽기” 기술
👉 저장공간 절약 + 쿼리 성능 향상 + 아카이브 데이터 관리에 최적.
- 자주 조회하지만 자주 수정되지 않는 데이터에 적합.
- Exadata 환경에서 Smart Scan과 Storage Index와 함께 쓰면 성능 효과가 폭발적입니다 🚀