[Exadata day3] 자원 및 성능 관리 (IORM & 성능 튜닝 & Smart Scan 실행 조건 및 모니터링)
🧠 7~9장: 자원 및 성능 관리
- 7장: I/O Resource Management (IORM) 계획 및 모니터링
- 8장: 성능 튜닝(PMEM/Flash, In-Memory Columnar, Latency Capping)
- 9장: Smart Scan 실행 조건 및 모니터링 방법
오늘 배운 내용 요약정리
7장: I/O Resource Management (IORM) 계획 및 모니터링
IORM ?
I/O Resource Management
👉 여러 종류의 워크로드(Workload)가 하나의 Exadata 환경을 공유할 때
* 워크로드 (EX) 1. OLTP (온라인 트랜잭션) 2.분석(Reporting) 3.ETL (배치 작업) 4.테스트 및 개발
👉 동시에 I/O를 요청하면 발생하는 경쟁에서,
각 워크로드에 공정하고 예측 가능한 I/O 자원 할당을 보장하는 핵심 기술
즉, 중요한 워크로드에 우선순위를 부여하거나, 비율대로 자원을 나누는 역할을 한다.
예를 들어, 하나의 Exadata에 아래와 같은 워크로드가 있다고 해봅시다👇
DB1: OLTP / Reporting
DB2: ETL / Batch
IORM Category Plan 예시:
Category Interactive (OLTP, Reporting) → 70%
Category Batch (ETL) → 30%
IORM 동작:
총 I/O 자원 100% 중 Interactive Category → 70% 우선 배정 Batch Category → 30% 배정
👉 OLTP 요청이 몰릴 경우, IORM이 자동으로 Batch의 I/O를 제한하고 OLTP에 우선순위를 줍니다.
IORM 핵심 개념 요소
Workload ?
데이터베이스에서 실행되는 작업 (OLTP, Batch, ETL 등)
Consumer Group ?
특정 워크로드를 묶어 관리하는 그룹 (DB 내부 단위)
Category ?
여러 DB에 걸친 Consumer Group을 묶는 상위 단위 (IORM 단위)
Resource Plan ?
자원 할당 정책 (비율, 우선순위 등) 정의
Objective ?
IORM이 자원을 관리하는 목표 모드 (basic, auto, balanced, low_latency 등)
8장 성능 최적화.
성능 최적화(Performance Optimization) 시 고려해야 할 핵심 영역
PMEM 초저지연 읽기 성능 향상 OLTP 속도 ↑
Flash Cache 핫데이터 캐싱 디스크 I/O 감소
In-memory Cache Column Store DW 분석 속도 ↑
Compression Hybrid Columnar Compression 공간 절감 + I/O 절감
Index 전략적 최소화 불필요한 오버헤드 제거
ASM 설정 AU/Extent 조정 I/O 효율 최적화
시스템 통계 Exadata 전용 지표 모니터링 병목 정확히 파악
Timeout 설정 환경별 튜닝 장애 감지 및 안정성 확보
PMEM Cache Mode 종류
🟢 Write-Through
(기본/권장)데이터가 PMEM과 Flash/HDD에 동시에 기록됨안정성 높음, 데이터 유실 위험 없음대부분의 운영 환경
🟡 Write-Back
고성능 모드먼저 PMEM에 쓰고 나중에 Flash/HDD로 내림응답속도 향상, 장애 시 데이터 손실 위험 있음성능 테스트나 극단적 저지연이 필요한 경우
9장 스마트 스캔 실행조건 및 모니터링 방법
Smart Scan ?
Exadata의 스토리지 오프로딩(Storage Offload) 기능
👉 스캔 작업을 DB 서버가 아니라 스토리지 셀에서 처리하여
👉 네트워크 트래픽을 줄이고, 쿼리 성능을 획기적으로 높이는 기능
그런데 아래와 같은 상황에서는 Smart Scan이 비활성화되어 전통적인 블록 기반 I/O로 처리되기 때문에 성능 향상을 기대할 수 없다.
1. Clustered Table
스캔 클러스터 테이블은 저장 구조가 일반 테이블과 달라서 스토리지 셀에서 효율적 오프로딩 불가
2. Index-Organized Table(IOT)
데이터가 인덱스에 직접 저장되는 구조라 Smart Scan 대상이 아님
3. 압축 인덱스의 Fast Full Scan
스토리지 셀에서 압축 인덱스를 해제하며 스캔하는 기능 미지원
4. Reverse Key Index Fast Full Scan
Reverse Key는 정렬 순서가 뒤섞여 있어 스토리지에서 순차 스캔 불가능
5. Row-level dependency tracking활성화된 테이블
내부적인 추가 메타데이터 관리로 오프로딩 불가능
6. ROWID 순서로 결과 반환
정렬 순서를 보장하기 위해 블록 단위 전송 필요
7. CREATE INDEX ... NOSORT
인덱스 생성 시 기존 데이터 정렬 유지로 Direct Path Read 미발생
8. LOB / LONG 컬럼이 포함된 쿼리
LOB/LONG은 Smart Scan 대상에서 제외됨 (길이가 크고 처리 방식 다름)
9. Flashback Versions Query 사용 시
Undo 데이터 접근 필요로 스토리지 오프로딩 불가
10. 255개 초과 컬럼 참조
Smart Scan의 최대 컬럼 처리 제한 초과
11. Tablespace가 암호화되어 있고, 셀 기반 복호화가 비활성화된 경우
DB 서버에서 복호화를 해야 하므로 Smart Scan 불가
12. Virtual Column 기반 Predicate 사용
가상 컬럼은 스토리지 셀에서 계산 불가(논리식 평가 필요)
모니터링 스마트 스캔 ?
V$SESSION_EVENT 세션단위로 스마트스캔이 일어났는지 확인 불가
v$system_event 시스템 단위로 스마트스캔 일어났는지 확은 가능함
but, 확인 방법은 처음 실행 후 다시 실행했을 때 스마트 스캔이 일어났는지 확인함
6216 -> 6509 아, 스마트스캔 실행됐구나 확인가능함
아니면 트레이스파일로 마스터프로세스랑 슬래이브프로세스가 실행한 걸 확인하여 알 수도 있음
I/O Resource Management

**I/O Resource Management(IORM)**가 왜 중요한지를 이해하는 핵심 개념입니다.
즉, **스토리지를 여러 데이터베이스와 워크로드가 공유(Shared Storage)**할 때의
✅ 장점과 ⚠️ 단점을 설명하고, 왜 IORM이 필수적인 관리 도구인지 연결되는 주제입니다.
🧭 1. Shared Storage란?
📌 여러 데이터베이스(혹은 여러 워크로드)가 동일한 스토리지 시스템을 공유하여 사용하는 구조
Exadata 환경에서는 DB 서버 여러 개가 하나의 스토리지 셀 풀(Pool)을 공유하는 게 일반적입니다👇
🧮 2. Shared Storage의 주요 장점
✅ (1) 스토리지 자원 활용도 향상
- 하나의 DB만 사용하는 전용 스토리지일 경우 → 최대 피크 용량 기준으로 과다 설계해야 함
- 하지만 실제 사용량은 들쭉날쭉 → 자원 낭비 발생
- 공유 스토리지를 사용하면, 여유 자원을 다른 DB가 활용 가능함
👉 예시:
- DB1이 오전에만 트래픽이 몰림
- DB2는 오후에만 트래픽이 있음
- 하나의 스토리지 풀에서 DB1, DB2가 자원을 시간대별로 나눠 쓰면 더 효율적입니다.
✅ (2) 운영 및 관리 비용 절감
- 스토리지 시스템을 DB마다 따로 둘 필요가 없음
- 유지보수 대상 장비 수가 줄어듦 → 관리 인력 및 비용 절감
- 자원 풀링(Pooling)으로 향후 확장성도 용이
⚠️ 3. Shared Storage의 단점 및 문제점
공유 환경은 자원 효율성을 높이는 대신, 경쟁이 발생할 수 있습니다.
⚡ (1) 워크로드 간 간섭 (Resource Contention)
- 한 DB에서 대규모 병렬 쿼리가 실행되면,
다른 DB의 중요한 트랜잭션 성능이 급격히 떨어질 수 있음.
👉 예시:
- DB1: 대형 보고서 쿼리 (Full Table Scan)
- DB2: 실시간 주문 트랜잭션
→ DB1이 I/O를 독점하면 DB2의 응답 속도가 느려짐.
⚡ (2) 워크로드 간 우선순위 조정 어려움
- 수작업으로 스케줄링하거나 시간대를 나눠야 하는 경우 발생
- 특히 관리자가 여러 명일 경우 조율이 쉽지 않음
- “나는 분석 작업 해야 한다”
- “나는 서비스 트랜잭션이 먼저다”
👉 이로 인해 피크 시간대에는 성능 병목(bottleneck)이 빈번히 발생합니다.
⚡ (3) 과잉 프로비저닝(Over-Provisioning)의 유혹
- 문제를 해결하기 위해 스토리지를 더 크게 구축하는 경우가 많음
- 하지만 이건 결국 **공유의 장점(비용 절감)**을 무력화시키는 결과가 됩니다.
🧠 4. IORM이 필요한 이유 (해결책)
Oracle I/O Resource Manager (IORM)은 바로 위의 문제를 해결하기 위해 설계되었습니다.
| 특정 워크로드가 I/O 독점 | Consumer Group / Category 기반 자원 비율 설정 |
| 워크로드 우선순위 충돌 | Priority 설정으로 중요한 워크로드에 우선권 부여 |
| 피크 시간대 충돌 | Category Plan을 통해 자동 자원 분배 |
| 관리자 간 충돌 | 정책 기반으로 자동화, 수동 조율 최소화 |
👉 예를 들어, OLTP 업무에 높은 우선순위를 부여하고, ETL이나 Batch는 남는 자원만 사용하게 설정 가능.
🧪 5. 예시: IORM Category Plan으로 해결
두 개의 DB가 공유 스토리지에서 운영 중이라고 가정👇
| DB1 | 실시간 OLTP | Interactive | 70% |
| DB2 | Batch 분석 | Batch | 30% |
IORM 설정 (CellCLI):
👉 피크 시간대에 OLTP가 몰려도 DB2는 자원을 뺏기지 않고 설정된 범위 내에서만 사용하게 됩니다.
📈 6. Shared Storage + IORM = 균형 잡힌 구조
| 성능 | 비정상적 워크로드에 의해 흔들림 | 안정적, 우선순위 보장 |
| 자원 사용 | 비효율적 / 편중됨 | 공정하게 분배됨 |
| 관리 방식 | 수작업, 시간대 분리 | 자동 정책 기반 할당 |
| 비용 | 과잉 투자 유도 가능 | 최소 자원으로 최적 활용 가능 |
✅ 7. 정리
- 📦 Shared Storage는 자원 효율성과 관리비 절감이라는 장점이 있지만,
⚡ 워크로드 충돌이라는 구조적 리스크가 존재합니다. - ⚙️ IORM은 이러한 충돌을 자동으로 관리하고, 우선순위 기반 자원 분배를 통해 성능을 보장합니다.
- 🔸 실제 운영에서는 Consumer Group + Category + CDB Resource Plan을 조합하여 유연하게 제어합니다.
I/O Resource Management Concepts

I/O Resource Management (IORM)**는
👉 여러 종류의 워크로드(Workload)가 하나의 Exadata 환경을 공유할 때
👉 각 워크로드에 공정하고 예측 가능한 I/O 자원 할당을 보장하는 핵심 기술입니다.
아래에 개념을 아주 쉽게 정리해드릴게요👇
🧭 1. 왜 IORM이 필요한가?
현실의 데이터베이스 환경에는 다양한 워크로드가 공존합니다.
예:
- 🧑💼 OLTP (온라인 트랜잭션)
- 📊 분석(Reporting)
- 🧱 ETL (배치 작업)
- 🧪 테스트 및 개발
👉 이런 워크로드가 동시에 I/O를 요청하면 경쟁이 발생합니다.
👉 IORM은 이 경쟁 상황에서 중요한 워크로드에 우선순위를 부여하거나, 비율대로 자원을 나누는 역할을 합니다.
🧠 2. IORM 핵심 개념 요소
| Workload | 데이터베이스에서 실행되는 작업 (OLTP, Batch, ETL 등) |
| Consumer Group | 특정 워크로드를 묶어 관리하는 그룹 (DB 내부 단위) |
| Category | 여러 DB에 걸친 Consumer Group을 묶는 상위 단위 (IORM 단위) |
| Resource Plan | 자원 할당 정책 (비율, 우선순위 등) 정의 |
| Objective | IORM이 자원을 관리하는 목표 모드 (basic, auto, balanced, low_latency 등) |
🏗 3. Consumer Group과 Category
🧱 Consumer Group
- 데이터베이스 내에서 특정 워크로드를 그룹화
- 예: OLTP_GROUP, REPORT_GROUP, ETL_GROUP
🪜 Category
- 여러 DB의 Consumer Group을 카테고리 단위로 통합
- 예: Interactive (OLTP 중심), Batch (야간 배치 중심)
👉 이를 통해 Exadata는 DB 간에도 자원을 우선순위에 따라 배분할 수 있습니다.
📊 4. Resource Plan의 종류
| Intradatabase Plan | 단일 DB 내 Consumer Group 간 자원 배분 | |
| Interdatabase Plan | 여러 DB 인스턴스 간 자원 배분 | |
| Category Plan | 여러 DB에 걸친 Category 간 자원 배분 | |
| CDB Resource Plan | 하나의 CDB 안에서 PDB 간 자원 배분 (멀티테넌트) |
👉 이 네 가지 Plan은 IORM 레벨에서 동시에 작동할 수 있으며, 계층적으로 영향을 미칩니다.
⚡ 5. 작동 방식 예시
예를 들어, 하나의 Exadata에 아래와 같은 워크로드가 있다고 해봅시다👇
- DB1: OLTP / Reporting
- DB2: ETL / Batch
IORM Category Plan 예시:
- Category Interactive (OLTP, Reporting) → 70%
- Category Batch (ETL) → 30%
IORM 동작:
👉 OLTP 요청이 몰릴 경우, IORM이 자동으로 Batch의 I/O를 제한하고 OLTP에 우선순위를 줍니다.
🧪 6. 실무 설정 예시
📜 Category Plan 생성 및 적용 (CellCLI)
👉 objective=auto는 자동으로 I/O를 분배하면서 OLTP 워크로드를 우선하는 모드입니다.
📈 7. 모니터링 예시
IORM Plan 확인:
Category 사용량 모니터링:
DB Resource Plan 확인:
🧭 8. IORM Objective 설정 모드
| basic | IORM 비활성 상태 (모든 워크로드가 자원 공유) |
| auto | 자동 우선순위 및 할당 (권장 기본값) |
| balanced | 균형 있게 분배 |
| low_latency | 지연 시간 최소화에 집중 (OLTP에 적합) |
👉 auto 모드에서 가장 유연하게 Category / Consumer Group / CDB Plan이 작동합니다.
✅ 9. 요약 정리
| IORM 목적 | 여러 워크로드가 공존할 때 자원 경쟁을 제어 |
| Consumer Group | DB 내부에서 워크로드 구분 |
| Category | 여러 DB에 걸친 워크로드 그룹화 |
| Resource Plan | 자원 할당 정책 정의 (Intradatabase, Interdatabase, Category, CDB) |
| Objective | 관리 목표 설정 (auto 권장) |
| 결과 | 예측 가능한 성능, 중요한 워크로드 우선 보장 🚀 |
👉 한 줄 요약:
IORM = Exadata에서 I/O 자원을 워크로드별로 공정하고 전략적으로 분배하는 엔진입니다.
Consumer Group + Category + Resource Plan을 조합하면 복잡한 환경에서도 성능을 안정적으로 유지할 수 있습니다 🧠⚡
I/O Resource Management Plans
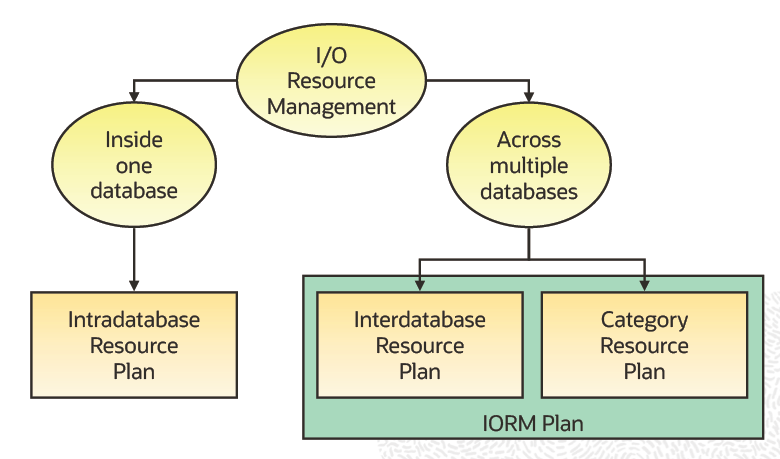
Oracle Exadata의 I/O Resource Manager (IORM) 가
어떻게 여러 가지 방식으로 I/O 자원 할당을 관리할 수 있는지 설명하는 핵심 개념입니다.
IORM에는 3가지 주요 접근 방식이 있으며,
👉 각각 단독으로도 사용 가능하고,
👉 상황에 따라 조합해서 동시에 운영할 수도 있습니다.
아래에 개념을 체계적으로 정리해드릴게요👇
🧭 1. IORM 접근 방식 개요
| ① Intradatabase | 단일 데이터베이스 내부의 워크로드 | DB Resource Manager | 워크로드(OLTP, Batch 등) 간 자원 배분 |
| ② Interdatabase | 여러 데이터베이스 간 | IORM Plan (cell level) | DB별 자원 할당 |
| ③ Category | 여러 DB에 걸친 공통 workload 유형 | IORM Plan (cell level) | 업무 카테고리(OLTP/Report/ETL 등)별 자원 할당 |
🧱 2. ① Intradatabase Resource Management
📌 하나의 데이터베이스 안에서 여러 workload를 제어할 때 사용
예:
- 한 DB 안에 OLTP, Reporting, ETL 작업이 동시에 실행
- OLTP가 우선이므로 더 많은 I/O 비중을 부여하고, 나머지 작업은 제한
구성:
- Consumer Group 생성 (ex. OLTP_GROUP, REPORT_GROUP)
- DB Resource Manager로 비중 설정
- Plan 활성화
예시:
👉 Intradatabase는 단일 DB 환경에서 가장 기본적으로 쓰이는 방식입니다.
🧭 3. ② Interdatabase Resource Management
📌 여러 개의 데이터베이스가 하나의 Exadata 스토리지를 공유할 때, DB별 자원 할당을 제어
예:
- Exadata 한 대에 DB1(OLTP)와 DB2(DW)가 함께 올라가 있음
- OLTP가 우선이므로 DB1에 70%, DB2에 30% 할당
구성:
- IORMPLAN에서 DB별 directive 정의
- Interdatabase Plan 생성
예시 (CellCLI):
👉 이 방식은 데이터베이스 단위로 자원을 공정하게 나누는 역할을 합니다.
🪜 4. ③ Category Resource Management
📌 **워크로드의 성격(카테고리)**에 따라 자원을 나누는 고급 기능
예:
- 모든 DB에서 OLTP / REPORT / MAINTENANCE 세 가지 workload가 있음
- OLTP가 가장 중요 → Category별로 자원 비중 설정
구성:
- 각 Consumer Group을 Category에 매핑
- Category Plan에서 Category별 비중 설정
예시 (CellCLI):
👉 Category Plan은 DB 간이 아니라 업무 성격 기준으로 자원을 분배할 수 있어 대규모 공유 환경에 유리합니다.
⚡ 5. 3가지 방식의 조합
IORM은 이 세 가지 방식을 계층적으로 조합해서 작동시킬 수 있습니다.
예:
- Category Plan: OLTP > REPORT
- Interdatabase Plan: DB1 70% / DB2 30%
- Intradatabase Plan (DB1 내부): OLTP 80% / ETL 20%
👉 이렇게 하면 복잡한 멀티워크로드 환경에서도 정교하게 자원을 통제할 수 있습니다.
🧪 6. IORM Plan 확인 및 관리 명령
IORM Plan 상태 확인:
현재 설정된 Category/DB별 할당 확인:
DB 내부 Consumer Group 확인:
✅ 7. 요약 정리
| Intradatabase | 단일 DB 내부 workload | DB Resource Manager | 간단, 유연 | 소규모 환경 |
| Interdatabase | 여러 DB 간 | Cell IORM Plan | DB 간 공정 배분 | 멀티 DB 환경 |
| Category | 여러 DB의 공통 workload | Cell IORM Plan | 업무 성격 기반 관리 | 대규모, 복합 workload 환경 |
👉 1개만 써도 되지만, 실무에서는 Interdatabase + Category + Intradatabase 조합이 많습니다.
👉 특히 금융/통신/공공기관 같이 OLTP + Batch + 분석이 동시에 도는 환경에서 빛을 발합니다 🌟

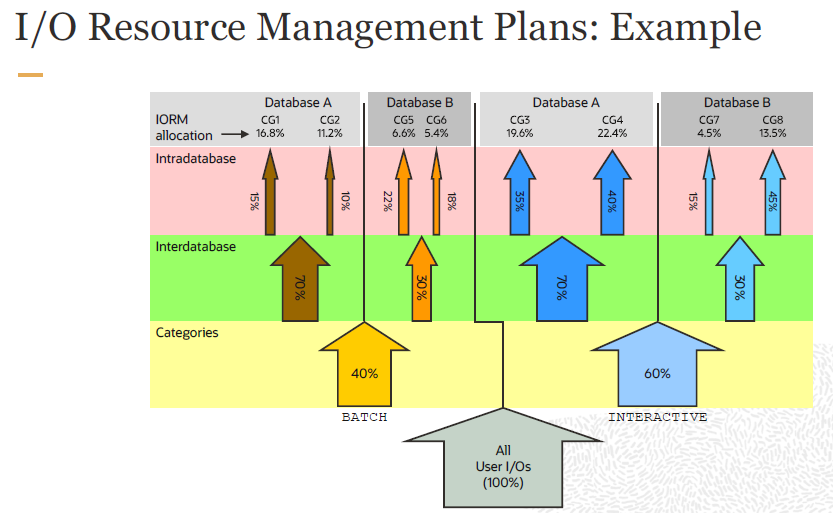
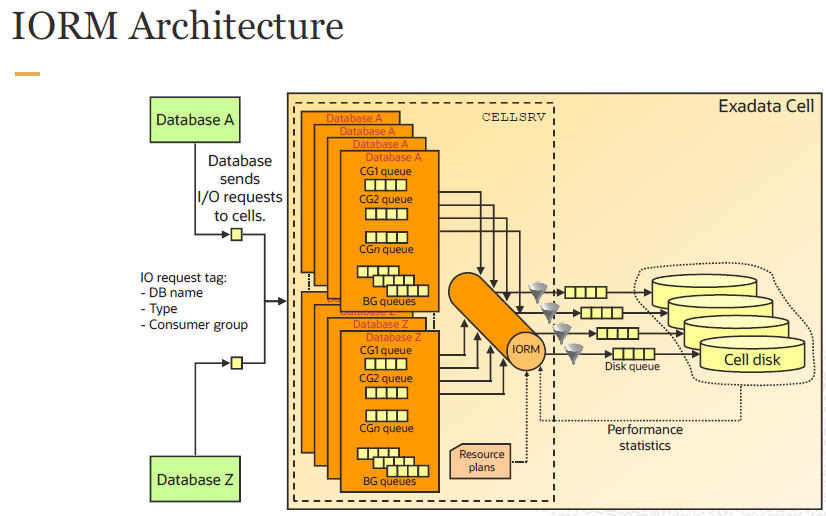














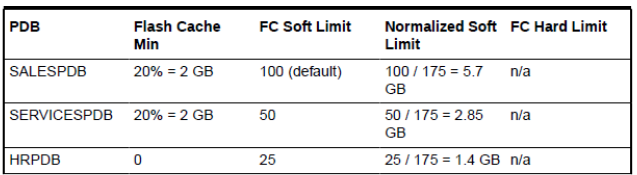

8장
Recommendations for Optimizing
Database Performance

Oracle Exadata 환경에서 성능 최적화(Performance Optimization) 시 고려해야 할 핵심 영역을 정리한 것입니다.
단순히 DB 튜닝만으로는 Exadata의 진가를 다 끌어내기 어렵기 때문에, Exadata 전용 기능과 스토리지 계층까지 함께 최적화하는 것이 중요합니다.
아래에 항목별로 구체적으로 설명드릴게요👇
🧭 1. 기본: ASM & Oracle Database Best Practices
- **ASM(Oracle Automatic Storage Management)**는 Exadata의 핵심 스토리지 가상화 계층입니다.
- DB 자체의 SQL 튜닝, 인덱스 설계, 통계 수집 등도 반드시 병행되어야 합니다.
- Exadata만의 성능 기능(PMEM, Flash, Smart Scan 등)은 “DB가 잘 설계되어 있을 때” 최대 효과를 냅니다.
👉 Exadata 성능 최적화는 “DB 튜닝 + 스토리지 계층 최적화”가 함께 가야 합니다.
⚡ 2. Persistent Memory (PMEM) 활용 최적화
- PMEM(지속성 메모리)은 DRAM보다 약간 느리지만 Flash보다 훨씬 빠름.
- RDMA(Remote Direct Memory Access) 기반으로 DB 서버에서 스토리지 셀의 PMEM에 초저지연 접근 가능.
- 자주 읽는 핵심 핫 데이터를 PMEM 캐시에 위치시켜 I/O 레이턴시 감소.
- 목표: Random I/O와 OLTP 트랜잭션 성능 향상.
👉 PMEM Cache를 잘 활용하면 OLTP 처리속도가 10배 이상 향상되는 경우도 있습니다.
💡 3. Flash Memory (Smart Flash Cache) 활용
- Flash Cache는 HDD보다 훨씬 빠른 중간 계층 캐시입니다.
- Smart Flash Cache는 자주 접근되는 블록을 자동으로 캐싱.
- 자주 조회되는 읽기 쿼리를 Flash에 위치시키면 디스크 I/O 감소.
- Flash Cache 크기와 정책(Write-back vs Write-through)을 환경에 맞게 조정.
👉 Flash Cache는 Exadata Smart Scan과도 연계되어 성능 최적화의 핵심 축입니다.
🧮 4. In-Memory Columnar Cache 활용
- Oracle Database In-Memory 기능을 사용하면 메모리에 Column Store를 유지 가능.
- Smart Scan과 결합하면 대규모 분석 쿼리의 응답 속도가 급격히 개선.
- 자주 분석되는 테이블(팩트 테이블 등)에 적합.
- Columnar 포맷은 압축 효율도 높아 I/O 절감에 유리.
👉 PMEM/Flash + In-memory Column Cache 조합이 대용량 DW 환경의 핵심 성능 전략입니다.
🪄 5. Compression 활용
- Exadata는 Hybrid Columnar Compression(HCC) 기능을 통해 압축 효율을 크게 높일 수 있음.
- Warehouse Compression: 쿼리 성능 중심
- Archive Compression: 최대 압축률 중심
- 압축은 단순히 저장공간 절감뿐 아니라, I/O 전송량 감소로 이어져 성능 향상 효과가 큽니다.
- 잘못 적용하면 CPU 부담이 증가할 수 있으므로 워크로드 특성에 맞게 선택 필요.
🧭 6. Index 사용 전략
- Exadata Smart Scan은 인덱스 없이도 대량의 Table Scan을 매우 빠르게 수행할 수 있음.
- 과도한 인덱스는 불필요한 관리 비용과 오버헤드만 유발할 수 있음.
- OLTP 워크로드에는 인덱스 필수, 대규모 분석 워크로드는 인덱스 최소화가 원칙.
👉 인덱스 설계는 Exadata에서 재검토가 필요합니다. 기존 DB 환경 그대로 가져오면 성능을 저해할 수 있습니다.
🧱 7. ASM Allocation Unit Size / Extent Size 최적화
- ASM Allocation Unit(AU) 크기와 Extent Size는 I/O 효율성에 직접적인 영향을 줍니다.
- 기본값은 보통 4MB인데, 대규모 DW 환경에서는 더 큰 AU가 유리할 수 있음.
- Extent size도 테이블 액세스 패턴에 따라 조정하여 Smart Scan 효율을 높일 수 있음.
👉 큰 I/O는 fewer calls, 더 빠른 처리. 작은 I/O는 OLTP에 유리. 워크로드에 맞춰 설계 필요.
📈 8. Exadata Specific System Statistics
- Exadata 전용 시스템 통계(v$cell, v$sysstat, v$cell_iorm_statistics 등)를 모니터링해야 진짜 병목을 찾을 수 있음.
- 주요 지표 예:
- cell physical IO bytes saved by storage index
- cell physical IO interconnect bytes returned by smart scan
- cell flash cache hits
- IORM statistics
👉 일반 DB 통계만 보면 Exadata의 스토리지 오프로딩 효과를 간과할 수 있습니다.
⏳ 9. I/O Timeout Threshold 설정
- 기본 I/O 타임아웃이 너무 짧으면 Flash/HDD 딜레이 시 불필요한 에러 발생
- 반대로 너무 길면 장애 감지가 느려짐
- 워크로드에 따라 적절한 I/O timeout 설정 필요 (특히 OLTP vs DW 환경 차이)
✅ 정리 요약
| PMEM | 초저지연 읽기 성능 향상 | OLTP 속도 ↑ |
| Flash Cache | 핫데이터 캐싱 | 디스크 I/O 감소 |
| In-memory Cache | Column Store | DW 분석 속도 ↑ |
| Compression | Hybrid Columnar Compression | 공간 절감 + I/O 절감 |
| Index | 전략적 최소화 | 불필요한 오버헤드 제거 |
| ASM 설정 | AU/Extent 조정 | I/O 효율 최적화 |
| 시스템 통계 | Exadata 전용 지표 모니터링 | 병목 정확히 파악 |
| Timeout 설정 | 환경별 튜닝 | 장애 감지 및 안정성 확보 |
👉 한 줄로 요약하면,
Exadata 성능 최적화는 “스토리지 계층까지 포함한 전체 아키텍처 튜닝”이 핵심입니다.
단순 SQL 튜닝만으로는 Exadata의 Smart 기능을 100% 활용할 수 없습니다 💪⚡
PMEM
Persistent Memory
Persistent Memory(PMEM) 는 최신 세대 Exadata에서 가장 큰 성능 혁신 포인트 중 하나입니다.
특히 초저지연 I/O가 필요한 OLTP 워크로드(예: 주식거래, IoT, 실시간 처리)에 강력한 효과를 줍니다 ⚡
아래에 PMEM의 개념, 구성 요소, 동작 방식, 운영 팁까지 쉽게 정리해드릴게요👇
🧭 1. Persistent Memory란?
- PMEM은 DRAM(메모리)과 Flash Storage의 중간 영역에 위치한 새로운 형태의 메모리입니다.
- 속도는 Flash보다 훨씬 빠르고, DRAM보다는 약간 느립니다.
- 전원이 꺼져도 데이터가 유지되는 특성이 있어 고속 캐시로 사용하기 적합합니다.
- Exadata에서는 PMEM을 Smart PMEM Cache와 Smart PMEM Log로 활용합니다.
| 속도 | 🔸 초고속 | 중간 | 최고 |
| 휘발성 | 비휘발성 | 비휘발성 | 휘발성 |
| 용도 | 캐시 + 로그 가속 | 일반 캐시 | DB 버퍼 |
⚡ 2. Smart PMEM Cache (Persistent Memory Data Accelerator)
📌 자주 읽히는 데이터를 PMEM에 캐싱해서 초저지연으로 제공하는 기능입니다.
- 디스크나 Flash보다 빠른 PMEM에 데이터를 저장해 읽기 속도 향상
- RDMA(Remote Direct Memory Access)를 이용해 DB 서버가 PMEM을 직접 접근
- OLTP 워크로드나 랜덤 읽기 부하에 효과적
- Smart Flash Cache와 유사하지만, PMEM이 더 빠름 (Flash 대비 수 μs 수준의 응답속도 개선)
✅ PMEM Cache 모드
| Write-Through | 데이터는 PMEM에 쓰고, 동시에 Flash/HDD에도 반영 | 안정성 높음, 권장 |
| Write-Back | 데이터는 PMEM에 먼저 쓰고 나중에 Flash로 내려감 | 성능은 높지만 관리 복잡 |
👉 일반적으로 운영 환경에서는 Write-Through 모드를 권장합니다.
🪄 3. Smart PMEM Log (Persistent Memory Commit Accelerator)
📌 PMEM을 Redo Log 쓰기 가속에 활용하는 기능입니다.
- 기존에는 redo log 기록 시 Flash Log를 사용해 지연을 줄였음
- PMEM Log는 Flash Log보다 더 빠른 속도로 redo 기록 지연(latency)을 줄임
- 트랜잭션 커밋(commit) 속도에 직접적으로 영향을 줌 → OLTP 성능 향상
- PMEM Log는 데이터베이스별로 활성화 또는 비활성화 가능함
👉 초저지연 커밋이 중요한 워크로드(금융 거래, IoT 센서 데이터 등)에 특히 효과적입니다.
🧰 4. PMEM 사용 대상 워크로드 예시
| 🏦 금융 트랜잭션 | 커밋 지연 최소화 필요 (PMEM Log 효과 극대화) |
| 📈 실시간 분석 | 자주 조회되는 데이터 빠른 응답 필요 |
| 🌐 IoT 센서 데이터 | 초저지연 쓰기 처리 필요 |
| 🏭 대규모 OLTP | 랜덤 읽기 부하 최적화 |
9장 스마트스캔
Smart Scan은 Exadata의 스토리지 오프로딩(Storage Offload) 기능으로,
👉 스캔 작업을 DB 서버가 아니라 스토리지 셀에서 처리하여
👉 네트워크 트래픽을 줄이고, 쿼리 성능을 획기적으로 높이는 기능입니다. ⚡
그런데 아래와 같은 상황에서는 Smart Scan이 비활성화되어 전통적인 블록 기반 I/O로 처리되기 때문에 성능 향상을 기대할 수 없습니다.
아래에 항목별로 왜 Smart Scan이 안 되는지까지 해설해드릴게요👇
🧭 1. Smart Scan이란? (간단 복습)
| 처리 위치 | 스토리지 셀 | DB 서버 |
| 전송량 | 필요한 컬럼/로우만 전송 | 전체 블록 전송 |
| 성능 | 빠름 (오프로딩) | 느림 |
| 효과 | 네트워크 부하 감소, CPU 절감 | 부하 집중 |
👉 Smart Scan은 Table Full Scan, Direct Path Read를 사용하는 경우에 주로 발생합니다.
⚠️ 2. Smart Scan이 동작하지 않는 상황
| 1. Clustered Table 스캔 | 클러스터 테이블은 저장 구조가 일반 테이블과 달라서 스토리지 셀에서 효율적 오프로딩 불가 |
| 2. Index-Organized Table(IOT) | 데이터가 인덱스에 직접 저장되는 구조라 Smart Scan 대상이 아님 |
| 3. 압축 인덱스의 Fast Full Scan | 스토리지 셀에서 압축 인덱스를 해제하며 스캔하는 기능 미지원 |
| 4. Reverse Key Index Fast Full Scan | Reverse Key는 정렬 순서가 뒤섞여 있어 스토리지에서 순차 스캔 불가능 |
| 5. Row-level dependency tracking 활성화된 테이블 | 내부적인 추가 메타데이터 관리로 오프로딩 불가능 |
| 6. ROWID 순서로 결과 반환 | 정렬 순서를 보장하기 위해 블록 단위 전송 필요 |
| 7. CREATE INDEX ... NOSORT | 인덱스 생성 시 기존 데이터 정렬 유지로 Direct Path Read 미발생 |
| 8. LOB / LONG 컬럼이 포함된 쿼리 | LOB/LONG은 Smart Scan 대상에서 제외됨 (길이가 크고 처리 방식 다름) |
| 9. Flashback Versions Query 사용 시 | Undo 데이터 접근 필요로 스토리지 오프로딩 불가 |
| 10. 255개 초과 컬럼 참조 | Smart Scan의 최대 컬럼 처리 제한 초과 oracle 1개 테이블 최대 가능 컬럼 1000개. 컬럼 255개 초과하면 스마트스캔 X |
| 11. Tablespace가 암호화되어 있고, 셀 기반 복호화가 비활성화된 경우 | DB 서버에서 복호화를 해야 하므로 Smart Scan 불가 |
| 12. Virtual Column 기반 Predicate 사용 | 가상 컬럼은 스토리지 셀에서 계산 불가(논리식 평가 필요) virtual column ? C as substr(a,1,4) |
🧪 3. Smart Scan 동작 여부 확인 방법
📊 SQL 실행 후 통계 확인
중요 지표:
- cell physical IO interconnect bytes returned by smart scan 👉 Smart Scan 발생 시 증가
- physical read total bytes 👉 전체 읽기량
👉 이 두 값을 비교하면 Smart Scan이 얼마나 적용됐는지 파악 가능
📜 실행 계획에서 확인
- TABLE ACCESS STORAGE FULL 이 나타나면 Smart Scan 발생 가능성 있음 ✅
- TABLE ACCESS FULL 만 있다면 일반 블록 I/O 🚫
🧠 4. Smart Scan이 안 될 때의 대안
| LOB/LONG 컬럼 | 필요한 컬럼만 선택하거나 SecureFiles LOB으로 전환 |
| 가상 컬럼 | 실제 컬럼으로 materialize 하거나 함수 기반 인덱스 검토 |
| 암호화 TS | Cell-based Decryption 활성화 (TDE + Exadata 기능) |
| ROWID 정렬 요구 | 정렬 제거 또는 옵티마이저 힌트 검토 |
| 255개 초과 컬럼 | 필요한 컬럼만 Projection |
👉 단순히 Smart Scan이 안 되는 상황을 피하는 것만으로도 성능 향상이 가능합니다.
📈 5. Smart Scan 성능 영향 비교 (예시)
| Smart Scan (오프로딩) | 500MB 테이블 중 50MB만 전송 | 낮음 | ⚡ 빠름 |
| 전통 블록 I/O | 500MB 전체 전송 | 높음 | ⏳ 느림 |
👉 Smart Scan을 쓰는 것만으로도 쿼리 응답 시간이 수 배~수십 배 빨라질 수 있음.
✅ 6. 정리 요약
| 일반 Heap Table Full Scan | ✅ | ❌ Clustered Table |
| Direct Path Read | ✅ | ❌ ROWID 순서 필요 |
| 지원 데이터 타입 | NUMBER, DATE, VARCHAR2 등 | ❌ LOB, LONG |
| 조건절 | 일반 Predicate | ❌ Virtual Column Predicate |
| 인덱스 | 테이블 Full Scan 기반 | ❌ Reverse Key, 압축 인덱스 Fast Full Scan |
👉 Smart Scan을 막는 요소를 제거하거나 회피하면, Exadata의 진짜 성능을 끌어낼 수 있습니다 ⚡
Smart Scan을 사용하는지 확인하려면 SQL 실행 계획과 관련 파라미터 설정을 잘 이해해야 합니다.
이를 위해 사용되는 대표적인 초기화 파라미터가 바로👇
- CELL_OFFLOAD_PROCESSING
- CELL_OFFLOAD_PLAN_DISPLAY
아래에 실무 기준으로 정리해드릴게요.
🧭 1. CELL_OFFLOAD_PROCESSING 파라미터
📌 역할
- Exadata Smart Scan(스토리지 오프로딩)을 활성화 또는 비활성화하는 파라미터입니다.
- FALSE로 설정하면 Smart Scan 기능이 꺼지고, 전통적인 블록 I/O 방식으로만 동작합니다.
- 세션 단위로도 제어할 수 있어 튜닝이나 테스트 환경에서 자주 사용됩니다.
| TRUE ✅ | Smart Scan 및 오프로딩 기능 활성화 (기본값) |
| FALSE ❌ | Smart Scan 비활성화 → 모든 스캔이 DB 서버에서 처리됨 |
🧪 설정 방법
✅ 세션 단위
🖥 시스템 전체
💡 쿼리 단위 (힌트 사용)
👉 특정 쿼리에서만 Smart Scan을 끄고 성능 차이를 비교할 때 유용합니다.
📊 Smart Scan 사용 여부 테스트 예시
👉 Smart Scan 활성화 후 v$sysstat 또는 EXPLAIN PLAN으로 확인
(Offload 발생 시 TABLE ACCESS STORAGE FULL 표시)
👉 Smart Scan 비활성화 후 동일 쿼리 실행 시 TABLE ACCESS FULL로 표시됨.
🧠 2. CELL_OFFLOAD_PLAN_DISPLAY 파라미터
📌 역할
- 실행 계획(EXPLAIN PLAN 또는 DBMS_XPLAN)에 **스토리지 오프로딩 정보(Offloaded Predicate)**를 표시할지 여부를 제어합니다.
- Smart Scan이 실제로 어떤 조건(Predicate)을 스토리지에서 평가했는지를 확인할 수 있음 → 튜닝 시 매우 중요⚡
| NEVER | 실행 계획에 오프로딩 정보 표시 안 함 |
| AUTO (기본값) | Smart Scan이 발생한 경우만 자동 표시 |
| ALWAYS | Smart Scan 여부와 관계없이 항상 표시 |
🧪 설정 방법
✅ 세션 단위
🖥 시스템 전체
📜 실행 계획에서 Smart Scan 정보 확인
CELL_OFFLOAD_PLAN_DISPLAY = ALWAYS로 설정되어 있으면, 아래와 같은 내용이 실행 계획에 나타납니다👇
👉 storage(...) 또는 offloadable predicate가 보이면 Smart Scan이 동작한 것입니다 ✅
🧪 3. 실무 튜닝에서의 활용 시나리오
| Smart Scan 활성화 확인 | CELL_OFFLOAD_PROCESSING=TRUE + 실행 계획 | 성능 활용 여부 파악 |
| Smart Scan 비활성화 후 비교 | CELL_OFFLOAD_PROCESSING=FALSE | 오프로딩 효과 측정 |
| 오프로딩된 조건 확인 | CELL_OFFLOAD_PLAN_DISPLAY=ALWAYS | Predicate Pushdown 튜닝 |
| 특정 조건 오프로딩 테스트 | OPT_PARAM 힌트 | 쿼리별 영향 분석 |
🧾 4. 자주 함께 쓰는 진단 쿼리
📊 Smart Scan 통계 확인
중요 지표:
- cell physical IO interconnect bytes returned by smart scan
- cell physical IO bytes eligible for predicate offload
- cell physical IO bytes saved by storage index
👉 Smart Scan이 제대로 동작할수록 interconnect bytes가 작고 saved by storage index가 증가합니다.
✅ 정리 요약
| CELL_OFFLOAD_PROCESSING | Smart Scan 기능 on/off | TRUE / FALSE | Smart Scan 활성화 여부 제어 |
| CELL_OFFLOAD_PLAN_DISPLAY | 실행 계획에 오프로딩 정보 표시 | NEVER / AUTO / ALWAYS | Smart Scan 동작 세부정보 확인 가능 |
👉 Smart Scan 튜닝 시에는 다음 3단계를 활용하는 게 실무 팁입니다👇
- CELL_OFFLOAD_PROCESSING으로 Smart Scan on/off 비교
- CELL_OFFLOAD_PLAN_DISPLAY로 실제 Predicate Pushdown 확인
- v$sysstat 및 실행 계획을 통해 I/O 절감 효과 측정 📊
**Oracle Exadata**에서 Smart Scan이 실행 계획에 표시된다고 해서 무조건 스토리지 오프로딩이 완벽히 적용되는 건 아닙니다.
실제 운영 환경에서는 Smart Scan이 부분적으로만 동작하거나 비활성화되는 상황도 종종 발생합니다.
이런 경우 원인을 파악하지 않으면 성능이 기대치만큼 나오지 않기 때문에, 실행 계획만 보는 것보다 통계와 Wait Event 분석까지 함께 해야 합니다.
아래에 상황별로 정리해드릴게요👇
🧭 1. “STORAGE”가 보인다고 무조건 Smart Scan이 아님 ⚠️
실행 계획에서👇
이렇게 보이더라도 다음과 같은 이유로 Smart Scan이 완전히 적용되지 않을 수 있습니다.
👉 즉, 실제로는 Block I/O가 일부 또는 전부 사용될 수도 있다는 뜻입니다.
⚠️ 2. Smart Scan이 부분적으로만 동작하는 주요 상황
| ① 블록의 최신 상태를 스토리지가 확신할 수 없는 경우 | 변경 가능성이 있는 블록은 Smart Scan으로 처리 불가 → 블록을 DB 서버로 전송해 버퍼 캐시에서 확인 | Smart Scan 부분 적용 |
| ② Chained / Migrated Rows 발생 | 한 행이 여러 블록에 걸쳐 있을 경우, Smart Scan으로는 완전한 로우 반환 불가 → 추가 블록 I/O 발생 | 성능 저하 |
| ③ Dynamic Sampling 발생 | 옵티마이저가 실행 전 샘플링을 위해 별도 I/O 수행 → Smart Scan 미사용 | 성능 예측치와 실제치 차이 |
| ④ 스토리지 서버 CPU 과부하 | 셀 서버의 CPU가 DB 서버보다 많이 사용되고 있으면 일부 처리를 DB로 되돌림 | 성능 하락 |
| ⑤ 데이터가 이미 버퍼 캐시에 존재 | Smart Scan이 필요 없어짐 → Buffer Cache Copy 사용 | 디스크 I/O 자체 미발생 |
| ⑥ Storage Server Quarantine 발생 | 문제가 된 스토리지 셀에서 Smart Scan이 비활성화됨 | Smart Scan 완전 차단 |
🧠 3. 각 상황에 대한 조금 더 구체적 설명
🪵 (1) Block Current Check
- Smart Scan은 기본적으로 **읽기 전용 데이터(consistent read)**에 최적화되어 있음.
- 블록이 변경되었거나 dirty 상태일 가능성이 있을 때, Exadata는 그 블록을 DB 서버로 전송해 버퍼 캐시에서 검증합니다.
👉 Smart Scan은 적용되지만, 추가 블록 I/O가 발생함.
🧱 (2) Chained / Migrated Rows
- 한 행이 여러 블록에 걸쳐 있으면, 스토리지 셀에서 완전한 레코드를 구성할 수 없음.
- Smart Scan으로 일부만 가져오고 나머지는 일반 Block I/O로 처리.
👉 테이블 설계나 PCTFREE 설정, 행 크기 조정 등을 통해 완화할 수 있음.
🧪 (3) Dynamic Sampling
- 옵티마이저가 실행 시점에 통계 샘플링을 위해 디스크에서 데이터를 읽는 경우 Smart Scan이 적용되지 않음.
- OPTIMIZER_DYNAMIC_SAMPLING 수준을 적절히 조정하거나 통계를 미리 수집하는 것으로 회피 가능.
🧠 (4) Storage CPU 부하
- 스토리지 셀에서 Smart Scan을 수행할 CPU가 충분하지 않으면, 일부 predicate를 DB 서버에서 처리하게 됨.
👉 스토리지 CPU 모니터링이 필요합니다 (cellcli metric 또는 AWR I/O 보고서 활용).
🧠 (5) Buffer Cache Hit
- Smart Scan은 디스크 I/O가 발생할 때만 작동합니다.
- 이미 데이터가 버퍼 캐시에 있으면, DB 서버가 캐시에서 데이터를 바로 반환 → Smart Scan 자체가 동작하지 않음.
🚨 (6) Storage Server Quarantine
- 스토리지 셀에 장애나 오류가 발생하면 Oracle이 자동으로 해당 셀을 격리(quarantine).
- 이 경우 Smart Scan은 비활성화되고, 일반 블록 I/O 경로로만 처리됨.
👉 셀 상태 복구 후 정상 동작 재개 필요.
🧾 4. Smart Scan 실제 동작 여부 확인 방법
단순히 실행 계획만으로는 부족하고 통계와 Wait Event를 같이 봐야 합니다.
📊 ① 실행 계획
- TABLE ACCESS STORAGE FULL → Smart Scan 가능성 존재
- 단, 확정은 아님 ❗
📊 ② 시스템 통계(v$sysstat)
중요 지표:
- cell physical IO interconnect bytes returned by smart scan
- cell physical IO bytes eligible for predicate offload
- cell physical IO bytes saved by storage index
👉 Smart Scan이 제대로 동작하면 interconnect bytes 값이 작고 predicate offload가 커짐.
📊 ③ Wait Events
대표적인 Smart Scan 관련 Wait Event:
- cell smart table scan
- cell smart index scan
👉 이 이벤트가 보이면 실제 Smart Scan이 발생한 것입니다.
🧠 5. 성능 분석 시 팁
| 실행 계획 | STORAGE 표시됨 | STORAGE 표시됨 |
| cell 통계 | Interconnect bytes ↓ | Interconnect bytes ↑ 또는 거의 없음 |
| Wait Event | cell smart table scan | db file sequential/scattered read 증가 |
| 스토리지 CPU | 여유 있음 | 과부하 발생 가능 |
| Buffer Cache | 적중률 적당 | 너무 높을 경우 Smart Scan 비활성 |
✅ 6. 요약 정리
| 실행 계획 | STORAGE FULL | 동일 (단서만 제공) |
| I/O 경로 | 대부분 스토리지 처리 | 일부 또는 전체 Block I/O 발생 |
| 대표 상황 | 대용량 Table Scan | 변경 블록, 체인 로우, Dynamic Sampling 등 |
| 진단 방법 | v$sysstat, Wait Event, 실행계획 | 통계/이벤트/스토리지 상태 함께 확인 |
👉 핵심 포인트:
실행 계획에 STORAGE가 보인다고 Smart Scan이 100% 적용되는 게 아닙니다.
실제 동작은 통계 + Wait Event + 스토리지 상태까지 함께 봐야 정확히 판단할 수 있어요.

service time = cpu time + wait time
cpu큰데, wait작다 ?
즉, 자원대기는 안하는데 cpu time 크다 ? 작업량 많은 상황 => 해결? sql튜닝
이럴 경우, 통계를 보면 안다.
statics : pysical & reads logical reads
cpu작은데, wait크다?
즉, 메모리 크게 변경 등, instanent 튜닝으로 해결
wait event : buffer busy waits => ASSM
Monitoring Exadata Smart Scan
V$SESSION_EVENT 세션단위로 스마트스캔이 일어났는지 확인 불가
=> v$system_event 시스템 단위로 스마트스캔 일어났는지 확은 가능함
but, 확인 방법은 처음 실행 후 다시 실행했을 때 스마트 스캔이 일어났는지 확인함
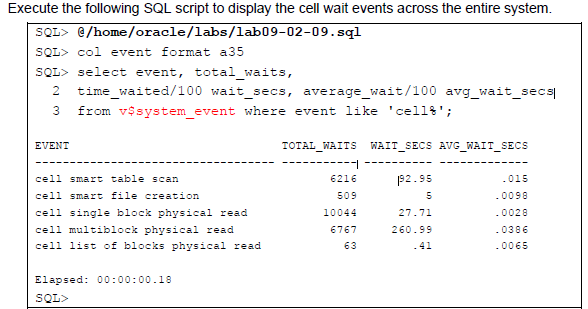

6216 -> 6509 아, 스마트스캔 실행됐구나 확인가능함
아니면 트레이스파일로 마스터프로세스랑 슬래이브프로세스가 실행한 걸 확인하여 알 수도 있음

