쓰기 패턴이 아주 강한 경우엔(옵션) Write-back 모드로 플래시에 먼저 기록 후 나중에 디스크로 내립니다.
(Redo 로그는 별도로 Smart Flash Log가 커밋 지연을 줄여줌)
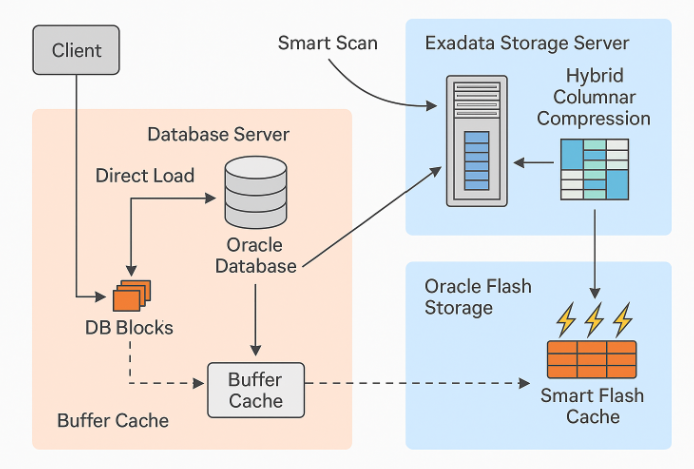
5) HCC(하이브리드 컬럼 압축): “공간도 성능도 아낀다”
DW/아카이브성 대용량 테이블은 종종 HCC로 압축되어 저장됩니다.
스토리지 셀이 압축 해제 및 필터링을 같이 해줘서, 압축된 데이터라도 적은 I/O로 많은 로우를 훑고, 필요분만 DB 서버로 보내요.
즉 “압축 + 오프로딩” 조합으로 디스크→네트워크→DB 서버 모든 구간의 부하를 감소시킵니다.
6) DB 서버: “받아서 마무리”
여러 스토리지 셀에서 온 가벼워진 결과셋을 DB 서버가 합치고(병렬 쿼리 결과 병합과 유사)
나머지 연산(정렬/집계 일부 등)을 마무리합니다.
7) 최종 결과 → 클라이언트
DB 서버가 결과를 클라이언트에게 반환.
블록 덩어리를 잔뜩 끌어오던 전통 방식보다 CPU·네트워크·디스크 I/O가 모두 절약됩니다.
그래서 더 빠른 쿼리, 더 많은 동시 처리가 가능해집니다.
핵심 키워드 한 줄 요약
Smart Storage/Smart Scan: 스토리지에서 미리 걸러서 필요한 것만 위로 보냄
iDB: DB ↔ 스토리지 셀 간 오프로딩 지시용 전용 프로토콜
Flash Cache: 자주 쓰는 데이터를 플래시에 캐싱해 읽기 가속
HCC: 고압축 + 스토리지 측 해제/필터링으로 I/O·네트워크 절감
(보너스) Smart Flash Log: Redo 커밋 지연 감소(OLTP에 효과)
언제 특히 효과적?
풀 스캔이 많은 DW/분석 쿼리: 조건/컬럼을 스토리지에서 미리 정리
대용량 테이블: HCC + Smart Scan으로 읽기량 대폭 감소
자주 반복 조회: Flash Cache로 랜덤 읽기 지연 최소화
언제 덜 쓰일 수 있나?
인덱스 소량 조회(OLTP형, PK=값 하나): 버퍼 캐시 히트가 더 유리할 수 있음
Smart Scan 비대상 객체/연산(예: 일부 LOB/가상컬럼/특정 인덱스 스캔 등)
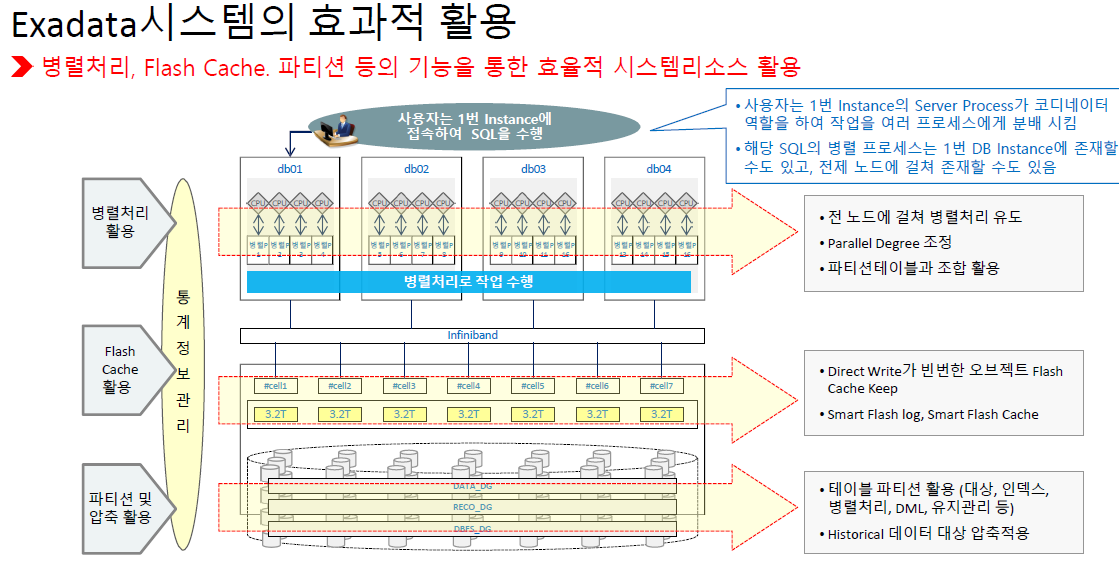
Exadata와 병렬 처리
✅ Smart Scan: PX Slave가 스토리지에서 필요한 데이터만 읽음 → I/O 대폭 감소
✅ Storage Offloading: 서버로 올라오는 데이터 량 줄임
✅ Flash Cache 병렬 읽기: 플래시에서 초고속 읽기
✅ InfiniBand / RoCE 네트워크: 병렬 노드 간 빠른 데이터 전송
👉 Exadata에서는 병렬 처리를 하면 CPU 부하가 덜하고, 속도 향상이 선형적으로 나오는 경우는 경우가 많음
병렬도(Degree of Parallelism, DOP)
DOP: 병렬로 작업할 PX 프로세스 개수
수동 설정 또는 자동 설정 가능
ALTERTABLE emp PARALLEL 8; -- 테이블에 병렬도 8 설정
또는 SQL 힌트로:
SELECT/*+ PARALLEL(emp, 8) */*FROM emp;
👉 병렬도 = PX Slave 수 👉 너무 높게 잡으면 CPU 과부하 발생하므로 주의 ⚠️
병렬 처리 관련 주요 파라미터
파라미터설명
PARALLEL_MAX_SERVERS
전체 병렬 Slave 프로세스 최대 수
PARALLEL_MIN_SERVERS
최소 프로세스 수
PARALLEL_DEGREE_POLICY
AUTO / MANUAL 병렬 정책
PARALLEL_MIN_TIME_THRESHOLD
병렬 실행으로 전환되는 기준 시간
PARALLEL_FORCE_LOCAL
병렬 실행 시 로컬 노드만 사용 여부
👉 특히 DW 환경에서는 PARALLEL_DEGREE_POLICY = AUTO 를 많이 사용합니다.
Exadata 병렬 SQL
작성법은 “객체 속성/힌트/세션 설정” 3가지를 쓴다.
대상은 큰 스캔/집계/적재(DW/배치).
Exadata에선 병렬 + Smart Scan/Direct Path/HCC가 맞물리며 효율이 기가 막히게 올라간다.
1) 기본 설정(세션/DB)
-- 자동 병렬화 권장 (Exadata에서 특히 효과적)ALTER SESSION SET parallel_degree_policy = AUTO; -- MANUAL이면 힌트/속성만 적용ALTER SESSION SET parallel_min_time_threshold =10; -- 10초↑ 추정 작업만 자동 병렬-- 병렬 DML 사용할 때ALTER SESSION ENABLE PARALLEL DML;
팁: 전역 기본값은 DBA가 PARALLEL_DEGREE_POLICY=AUTO 로 운영 설계하는 게 보통입니다.
2) 객체/SQL 단위 병렬 지정
(A) 객체(테이블/인덱스)에 병렬 속성 부여
ALTERTABLE sales PARALLEL 8; -- 테이블 기본 병렬도(DOP) 8ALTER INDEX sales_idx PARALLEL 8; -- 해제: ALTER TABLE sales NOPARALLEL;
(B) SQL 힌트로 병렬 지정(가장 흔함)
-- 대용량 SELECTSELECT/*+ PARALLEL(sales, 8) */*FROM sales WHERE txn_date >=DATE'2025-01-01'; -- CTAS (Create Table As Select)CREATETABLE sales_y25 NOLOGGING PARALLEL 16ASSELECT/*+ PARALLEL(16) */*FROM sales WHERE txn_date >=DATE'2025-01-01'; -- INSERT APPEND (Direct Path + 병렬 적재)ALTER SESSION ENABLE PARALLEL DML; INSERT/*+ APPEND PARALLEL(sales_y25, 16) */INTO sales_y25 SELECT/*+ PARALLEL(sales, 16) */*FROM sales WHERE txn_date >=DATE'2025-01-01'; -- 병렬 UPDATE/DELETEALTER SESSION ENABLE PARALLEL DML; UPDATE/*+ PARALLEL(orders, 8) */ orders SET status ='CLOSED'WHERE order_dt < SYSDATE -90; DELETE/*+ PARALLEL(orders, 8) */FROM orders WHERE order_dt < SYSDATE -365;
실무 팁: 대량 로딩은 INSERT /*+ APPEND PARALLEL */ + NOLOGGING(복구정책 확인) 조합을 많이 씁니다.
3) 분배 전략 힌트(PX간 데이터 이동 최적화)
-- 조인 키 기준 해시 분배(많이 씀)SELECT/*+ PARALLEL(orders, 16) PARALLEL(customers, 16) PQ_DISTRIBUTE(orders HASH, customers HASH) */ ... FROM orders JOIN customers USING(customer_id); -- 작은 테이블 브로드캐스트(큰 테이블 스캔 최소화)SELECT/*+ PARALLEL(big_t, 16) PARALLEL(dim_t, 16) PQ_DISTRIBUTE(dim_t BROADCAST, big_t HASH) */ ... FROM big_t JOIN dim_t USING(key);
파티션 테이블이면 Partition-wise Join(자연스럽게 발생)으로 데이터 재분배 최소화 → 성능↑
4) Exadata에서 잘 먹히는 패턴
큰 범위 스캔 + PARALLEL → Smart Scan 오프로딩으로 서버로 올라오는 데이터가 확 줄어듦
-- 실행계획에 PX 단계 확인SELECT*FROMTABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST +PARALLEL')); -- PX 통계: 어떤 TQ(전송 큐)로 어떻게 분배됐는지 확인SELECT*FROM V$PQ_TQSTAT; -- 세션/시스템 병렬 서버 현황SELECT*FROM V$PX_SESSION; SELECT*FROM V$PX_PROCESS;
계획에서 PX COORDINATOR, PX SEND/RECEIVE, PX PARTITION 등이 보이면 병렬이 제대로 동작 중.
6) 성능/안정성 체크리스트
대상 선정: 수백 GB~TB급 스캔·집계/적재 작업에만 병렬. OLTP 단건 처리는 비권장.
DOP(병렬도): 코어수·I/O·동시 작업 수를 고려. 과도한 DOP는 경합/스케줄 지연 초래.
소테이블 브로드캐스트 주의: 작은 줄 알았던 테이블이 커지면 오히려 병목 → 분배 전략 재점검
7) 자주 쓰는 스니펫 모음
-- ① 테이블 기본 병렬도와 NOLOGGINGALTERTABLE fact_sales PARALLEL 16 NOLOGGING; -- ② CTAS로 분할/정렬까지 한 번에CREATETABLE fact_sales_y25 PARALLEL 16 NOLOGGING TABLESPACE data_ts ASSELECT/*+ PARALLEL(16) *//* 필요한 컬럼만 선택 + 파티션 키 기준 정렬/필요 시 가공 */*FROM fact_sales WHERE sales_dt >=DATE'2025-01-01'; -- ③ 인덱스 병렬 생성CREATE INDEX fact_sales_y25_ix1 ON fact_sales_y25(customer_id) PARALLEL 16 NOLOGGING; -- ④ 병렬 MERGE (대량 업서트)ALTER SESSION ENABLE PARALLEL DML; MERGE/*+ PARALLEL(t, 12) PARALLEL(s, 12) */INTO tgt t USING src s ON (t.key = s.key) WHEN MATCHED THENUPDATESET ... WHENNOT MATCHED THENINSERT (...); -- ⑤ 큰 조인에서 분배 전략 명시SELECT/*+ PARALLEL(a, 12) PARALLEL(b, 12) PQ_DISTRIBUTE(a HASH, b HASH) */ ... FROM big_a a JOIN big_b b ON b.k = a.k;